Generated 2026-03-22 09:48:03 — clean — 12 sites evaluated
| Site | Category | Overall | Intrusion | Anchor | Must-not | Timing |
|---|---|---|---|---|---|---|
| substack_mauboussin | newsletter | 0.35 (FAIL) | 0.50 | 0.00 | 1.00 | 429ms |
| stratechery_sample | newsletter | 0.50 (WARN) | 1.00 | 0.00 | 1.00 | 904ms |
| a16z_ai_apps | blog | 0.70 (WARN) | 0.00 | 1.00 | 1.00 | 8,131ms |
| sequoia_600b | blog | 0.85 (OK) | 0.50 | 1.00 | 1.00 | 7,655ms |
| arxiv_attention | academic | 0.85 (OK) | 0.50 | 1.00 | 1.00 | 2,828ms |
| substack_waxman | newsletter | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 10,472ms |
| reuters_article | news | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 1,924ms |
| paulgraham | blog | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 3,644ms |
| medium_article | blog | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 11,470ms |
| python_docs | docs | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 3,843ms |
| hn_show | forum | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 216ms |
| anthropic_claude | corporate | 1.00 (OK) | 1.00 | 1.00 | 1.00 | 11,443ms |
| Category | Sites | Avg Overall | Avg Intrusion | Avg Anchor | Avg Must-not |
|---|---|---|---|---|---|
| academic | 1 | 0.85 | 0.50 | 1.00 | 1.00 |
| blog | 4 | 0.89 | 0.62 | 1.00 | 1.00 |
| corporate | 1 | 1.00 | 1.00 | 1.00 | 1.00 |
| docs | 1 | 1.00 | 1.00 | 1.00 | 1.00 |
| forum | 1 | 1.00 | 1.00 | 1.00 | 1.00 |
| news | 1 | 1.00 | 1.00 | 1.00 | 1.00 |
| newsletter | 3 | 0.62 | 0.83 | 0.33 | 1.00 |
Michael Mauboussin | Substack SubscribeSign in ## Page not found No posts
Michael Mauboussin | Substack SubscribeSign in ## Page not found No posts
**Published:** 2026-03-18T06:00:00-04:00 ## 404 This page could not be found. Maybe try a search? Search Search×
**Published:** 2026-03-18T06:00:00-04:00 ## 404 This page could not be found. Maybe try a search? Search Search×
**Published:** 2026-01-08T21:08:13+00:00 Consumer # Notes on AI Apps in 2026 Anish Acharya Posted January 8, 2026 Subscribe Share Share [Email](#) [X](#) [LinkedIn](#) [Facebook](#) [Hacker News](#) [WhatsApp](#) [Flipboard](#) [Reddit](#) #### Notes on AI Apps in 2026 Table of Contents Share Share [Email](#) [X](#) [LinkedIn](#) [Facebook](#) [Hacker News](#) [WhatsApp](#) [Flipboard](#) [Reddit](#) I enjoyed the 2025 roundup pieces from [Karpathy](https://x.com/karpathy/status/2002118205729562949?s=20), [Simon](https://x.com/simonw/status/2006514122977063350?s=20) and many others, and they have me thinking about 2026. The AI Apps ecosystem is maturing in some expected ways and some surprising ones. We’ve figured out how to make code cheap, but it hasn’t yet diffused across the enterprise (or world) in the way that’s implied by the lower costs, and I don’t think we’ve realized even 10% of what that means for how companies get built and what software will exist. Meanwhile, there are still fundamental tooling problems to solve—like the fact that all our tools are for making, not for thinking. ### **Thinking tools vs Making tools** One big change I expect is the nature of tools themselves. All of the tools we use for knowledge work are focused on **execution:** IDEs for creating code, Figma for creating design, spreadsheets for creating models. When it comes to tools for **exploration** – tools that help us think – we don’t really have any modern products outside of how the LLMs themselves have emerged as thinking partners. As coding agents are able to work with increasing accuracy and longer time horizons, the hard problem moves from **how do I build it** to **what do I build.** You can imagine a near future PM who sets broad goals for their AI and wakes up every morning to review 2-3 features the model dreamt up, executed on, and A/B tested overnight. However in my experience the models are still not very good at deciding what to build next – the ideas are bland, derivative, and generally lack the spark you see from really good new product thinking. So I think the spiritual successors of coding tools, design tools, and productivity tools are very focused on **exploration vs execution.** Coding tools are already leading the way here; Cursor is the furthest along and I thought [Antigravity](https://antigravity.google/) was interesting in being “agent first” (exploration first) in their product design. ### **Software eats all the “service” functions in the organization** I’ve always noticed a distinction between “power” functions and “service” functions in software companies – power functions (engineering/product/performance marketing) tend to be closer to software, while service functions (legal/finance/HR) tend to be further from software and more human capital levered. Coding agents have two important implications for the enterprise. The first is that every team + every task (marketing, legal, procurement, finance) should be
**Published:** 2026-01-08T21:08:13+00:00 Consumer # Notes on AI Apps in 2026 Anish Acharya Posted January 8, 2026 Subscribe Share Share [Email](#) [X](#) [LinkedIn](#) [Facebook](#) [Hacker News](#) [WhatsApp](#) [Flipboard](#) [Reddit](#) #### Notes on AI Apps in 2026 Table of Contents Share Share [Email](#) [X](#) [LinkedIn](#) [Facebook](#) [Hacker News](#) [WhatsApp](#) [Flipboard](#) [Reddit](#) I enjoyed the 2025 roundup pieces from [Karpathy](https://x.com/karpathy/status/2002118205729562949?s=20), [Simon](https://x.com/simonw/status/2006514122977063350?s=20) and many others, and they have me thinking about 2026. The AI Apps ecosystem is maturing in some expected ways and some surprising ones. We’ve figured out how to make code cheap, but it hasn’t yet diffused across the enterprise (or world) in the way that’s implied by the lower costs, and I don’t think we’ve realized even 10% of what that means for how companies get built and what software will exist. Meanwhile, there are still fundamental tooling problems to solve—like the fact that all our tools are for making, not for thinking. ### **Thinking tools vs Making tools** One big change I expect is the nature of tools themselves. All of the tools we use for knowledge work are focused on **execution:** IDEs for creating code, Figma for creating design, spreadsheets for creating models. When it comes to tools for **exploration** – tools that help us think – we don’t really have any modern products outside of how the LLMs themselves have emerged as thinking partners. As coding agents are able to work with increasing accuracy and longer time horizons, the hard problem moves from **how do I build it** to **what do I build.** You can imagine a near future PM who sets broad goals for their AI and wakes up every morning to review 2-3 features the model dreamt up, executed on, and A/B tested overnight. However in my experience the models are still not very good at deciding what to build next – the ideas are bland, derivative, and generally lack the spark you see from really good new product thinking. So I think the spiritual successors of coding tools, design tools, and productivity tools are very focused on **exploration vs execution.** Coding tools are already leading the way here; Cursor is the furthest along and I thought [Antigravity](https://antigravity.google/) was interesting in being “agent first” (exploration first) in their product design. ### **Software eats all the “service” functions in the organization** I’ve always noticed a distinction between “power” functions and “service” functions in software companies – power functions (engineering/product/performance marketing) tend to be closer to software, while service functions (legal/finance/HR) tend to be further from software and more human capital levered. Coding agents have two important implications for the enterprise. The first is that every team + every task (marketing, legal, procurement, finance) should be
**Published:** 2024-06-20T19:44:15+00:00 # AI’s $600B Question The AI bubble is reaching a tipping point. Navigating what comes next will be essential. By [David Cahn](https://sequoiacap.com/people/david-cahn/) Published June 20, 2024 In September 2023, I published [AI’s $200B Question](https://sequoiacap.com/article/follow-the-gpus-perspective/). The goal of the piece was to ask the question: “Where is all the revenue?” At that time, I noticed a big gap between the revenue expectations implied by the AI infrastructure build-out, and actual revenue growth in the AI ecosystem, which is also a proxy for end-user value. I described this as a “$125B hole that needs to be filled *for each year of CapEx at today’s levels*.” This week, Nvidia completed its ascent to become the most valuable company in the world. In the weeks leading up to this, I’ve received numerous requests for the updated math behind my analysis. Has AI’s $200B question been solved, or exacerbated? If you run this analysis again today, here are the results you get: AI’s $200B question is now AI’s $600B question. 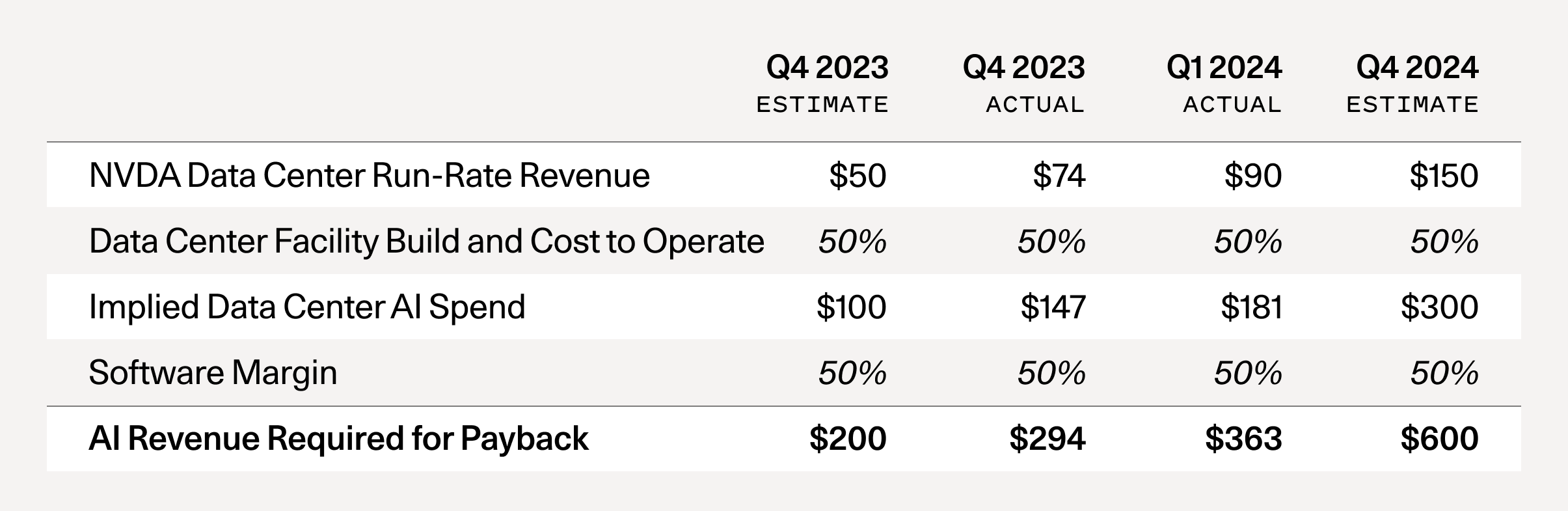 Note: It’s easy to calculate this metric directly. All you have to do is to take Nvidia’s run-rate revenue forecast and multiply it by 2x to reflect the total cost of AI data centers (GPUs are half of the total cost of ownership—the other half includes energy, buildings, backup generators, etc)1. Then you multiply by 2x again, to reflect a 50% gross margin for the end-user of the GPU, (e.g., the startup or business buying AI compute from Azure or AWS or GCP, who needs to make money as well). What has changed since September 2023? 1. **The supply shortage has subsided:** Late 2023 was the peak of the GPU supply shortage. Startups were calling VCs, calling anyone that would talk to them, asking for help getting access to GPUs. Today, that concern has been almost entirely eliminated. For most people I speak with, it’s relatively easy to get GPUs now with reasonable lead times. 2. **GPU stockpiles are growing:** Nvidia reported in Q4 that about half of its data center revenue came from the large cloud providers. Microsoft alone likely represented approximately [22% of Nvidia’s Q4 revenue](https://platformonomics.com/2024/02/follow-the-capex-triangulating-nvidia/comment-page-1/). Hyperscale CapEx is reaching historic levels. These investments were a major theme of Big Tech Q1 ‘24 earnings, with CEOs effectively telling the market: “We’re going to invest in GPUs whether you like it or not.” Stockpiling hardware is not a new phenomenon, and the catalyst for a reset will be once the stockpiles are large enough that demand decreases. 3. **OpenAI still has the lion’s share of AI revenue:** The Information recently reported that OpenAI’s revenue is now [$3.4B](https://www.theinformation.com/articles/openais-annualized-revenue-doubles-to-3-4-billion-since-late-2023?rc=0uxjjk), up from $1.6B in lat
**Published:** 2024-06-20T19:44:15+00:00 # AI’s $600B Question The AI bubble is reaching a tipping point. Navigating what comes next will be essential. By David Cahn Published June 20, 2024 In September 2023, I published AI’s $200B Question. The goal of the piece was to ask the question: “Where is all the revenue?” At that time, I noticed a big gap between the revenue expectations implied by the AI infrastructure build-out, and actual revenue growth in the AI ecosystem, which is also a proxy for end-user value. I described this as a “$125B hole that needs to be filled *for each year of CapEx at today’s levels*.” This week, Nvidia completed its ascent to become the most valuable company in the world. In the weeks leading up to this, I’ve received numerous requests for the updated math behind my analysis. Has AI’s $200B question been solved, or exacerbated? If you run this analysis again today, here are the results you get: AI’s $200B question is now AI’s $600B question.  Note: It’s easy to calculate this metric directly. All you have to do is to take Nvidia’s run-rate revenue forecast and multiply it by 2x to reflect the total cost of AI data centers (GPUs are half of the total cost of ownership—the other half includes energy, buildings, backup generators, etc)1. Then you multiply by 2x again, to reflect a 50% gross margin for the end-user of the GPU, (e.g., the startup or business buying AI compute from Azure or AWS or GCP, who needs to make money as well). What has changed since September 2023? 1. **The supply shortage has subsided:** Late 2023 was the peak of the GPU supply shortage. Startups were calling VCs, calling anyone that would talk to them, asking for help getting access to GPUs. Today, that concern has been almost entirely eliminated. For most people I speak with, it’s relatively easy to get GPUs now with reasonable lead times. 2. **GPU stockpiles are growing:** Nvidia reported in Q4 that about half of its data center revenue came from the large cloud providers. Microsoft alone likely represented approximately 22% of Nvidia’s Q4 revenue. Hyperscale CapEx is reaching historic levels. These investments were a major theme of Big Tech Q1 ‘24 earnings, with CEOs effectively telling the market: “We’re going to invest in GPUs whether you like it or not.” Stockpiling hardware is not a new phenomenon, and the catalyst for a reset will be once the stockpiles are large enough that demand decreases. 3. **OpenAI still has the lion’s share of AI revenue:** The Information recently reported that OpenAI’s revenue is now $3.4B, up from $1.6B in late 2023. While we’ve seen a handful of startups scale revenues into the <$100M range, the gap between OpenAI and everyone else continues to loom large. Outside of ChatGPT, how many AI products are consumers really using today? Consider how much value you get from Netflix for $15.49/month or Spotify for $11.99. Long term
# Computer Science > Computation and Language **arXiv:1706.03762** (cs) [Submitted on 12 Jun 2017 ([v1](https://arxiv.org/abs/1706.03762v1)), last revised 2 Aug 2023 (this version, v7)] # Title:Attention Is All You Need Authors:[Ashish Vaswani](https://arxiv.org/search/cs?searchtype=author&query=Vaswani,+A), [Noam Shazeer](https://arxiv.org/search/cs?searchtype=author&query=Shazeer,+N), [Niki Parmar](https://arxiv.org/search/cs?searchtype=author&query=Parmar,+N), [Jakob Uszkoreit](https://arxiv.org/search/cs?searchtype=author&query=Uszkoreit,+J), [Llion Jones](https://arxiv.org/search/cs?searchtype=author&query=Jones,+L), [Aidan N. Gomez](https://arxiv.org/search/cs?searchtype=author&query=Gomez,+A+N), [Lukasz Kaiser](https://arxiv.org/search/cs?searchtype=author&query=Kaiser,+L), [Illia Polosukhin](https://arxiv.org/search/cs?searchtype=author&query=Polosukhin,+I) View a PDF of the paper titled Attention Is All You Need, by Ashish Vaswani and 7 other authors [View PDF](/pdf/1706.03762) [HTML (experimental)](https://arxiv.org/html/1706.03762v7) > Abstract:The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data. | | | | --- | --- | | Comments: | 15 pages, 5 figures | | Subjects: | Computation and Language (cs.CL); Machine Learning (cs.LG) | | Cite as: | [arXiv:1706.03762](https://arxiv.org/abs/1706.03762) [cs.CL] | | | (or [arXiv:1706.03762v7](https://arxiv.org/abs/1706.03762v7) [cs.CL] for this version) | | | <https://doi.org/10.48550/arXiv.1706.03762> Focus to learn more arXiv-issued DOI via DataCite | ## Submission history From: Llion Jones [[view email](/show-email/f53b7360/1706.03762)] **[[v1]](/abs/1706.03762v1)** Mon, 12 Jun 2017 17:57:34 UTC (1,102 KB) **[[v2]](/abs/1706.03762v2)** Mon, 19 Jun 2017 16:49:45 UTC (1,125 KB) **[[v3]](/abs/1706.03762v3)** Tue, 20 Jun 2017 05:20:02 UTC (1,125 KB) **[[v4]](/abs/1706.03762v4)** Fri, 30 Jun 2017 17:29:30 UTC (1,12
# Computer Science > Computation and Language **arXiv:1706.03762** (cs) [Submitted on 12 Jun 2017 ([v1](https://arxiv.org/abs/1706.03762v1)), last revised 2 Aug 2023 (this version, v7)] # Title:Attention Is All You Need Authors:[Ashish Vaswani](https://arxiv.org/search/cs?searchtype=author&query=Vaswani,+A), [Noam Shazeer](https://arxiv.org/search/cs?searchtype=author&query=Shazeer,+N), [Niki Parmar](https://arxiv.org/search/cs?searchtype=author&query=Parmar,+N), [Jakob Uszkoreit](https://arxiv.org/search/cs?searchtype=author&query=Uszkoreit,+J), [Llion Jones](https://arxiv.org/search/cs?searchtype=author&query=Jones,+L), [Aidan N. Gomez](https://arxiv.org/search/cs?searchtype=author&query=Gomez,+A+N), [Lukasz Kaiser](https://arxiv.org/search/cs?searchtype=author&query=Kaiser,+L), [Illia Polosukhin](https://arxiv.org/search/cs?searchtype=author&query=Polosukhin,+I) View a PDF of the paper titled Attention Is All You Need, by Ashish Vaswani and 7 other authors [View PDF](/pdf/1706.03762) [HTML (experimental)](https://arxiv.org/html/1706.03762v7) > Abstract:The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data. | | | | --- | --- | | Comments: | 15 pages, 5 figures | | Subjects: | Computation and Language (cs.CL); Machine Learning (cs.LG) | | Cite as: | [arXiv:1706.03762](https://arxiv.org/abs/1706.03762) [cs.CL] | | | (or [arXiv:1706.03762v7](https://arxiv.org/abs/1706.03762v7) [cs.CL] for this version) | | | <https://doi.org/10.48550/arXiv.1706.03762> Focus to learn more arXiv-issued DOI via DataCite | ## Submission history From: Llion Jones [[view email](/show-email/f53b7360/1706.03762)] **[[v1]](/abs/1706.03762v1)** Mon, 12 Jun 2017 17:57:34 UTC (1,102 KB) **[[v2]](/abs/1706.03762v2)** Mon, 19 Jun 2017 16:49:45 UTC (1,125 KB) **[[v3]](/abs/1706.03762v3)** Tue, 20 Jun 2017 05:20:02 UTC (1,125 KB) **[[v4]](/abs/1706.03762v4)** Fri, 30 Jun 2017 17:29:30 UTC (1,12
**Published:** 2026-02-16T20:31:59+00:00 # Money at Machine Speed [](https://substack.com/@waxmand) [David Waxman](https://substack.com/@waxmand) Feb 16, 2026 6 3 1 Share --- Last week, Coinbase launched the first crypto wallet infrastructure built specifically for AI agents.¹ Hours later, Stripe announced it was adopting the same underlying protocol.² Two of the most important payments companies in the world shipped agent payment products on the same day. Thanks for reading! Subscribe for free to receive new posts and support my work. Subscribe We’ve spent the last few months researching this space at TenOneTen Ventures, and we think most people are underestimating how fast it’s moving. ## Agents Have a Money Problem We’ve gotten good at building AI agents that can reason, plan, and coordinate with each other. Impressively good. But there’s a comically basic thing most agents can’t do: pay for stuff. An agent finds the API it needs but can’t swipe a credit card. It negotiates with another agent but has no way to settle. It identifies cheaper cloud compute but can’t buy it. Every time money enters the picture, the agent stops and waits for a human. This is a little like building a fleet of self-driving trucks and then requiring a person to hand cash to every toll booth operator. The autonomy is real until the transaction isn’t. McKinsey projects $1 trillion in US retail agentic commerce by 2030, with global projections reaching $3–5 trillion.³ ChatGPT already handles over 50 million daily shopping queries.⁴ The demand is there. The plumbing to actually move money between machines is what’s been missing. Until, apparently, last week. ## What Agents Actually Need to Buy Before we get to who’s building what, it’s worth stopping on a point that most coverage of this space glosses over: the things agents need to pay for mostly don’t look like anything humans buy. Some of it is familiar. An agent booking a flight or ordering supplies — that’s just e-commerce with a different buyer. But the bigger and more interesting category is transactions that have no human equivalent at all. An agent needs a real-time pricing lookup from another agent’s database. That’s a fraction of a cent, settled instantly. It needs ten seconds of GPU time to run an inference. It needs to check a credit score, pull weather data for a logistics route, or access a proprietary dataset to answer a question. Each of these is a microtransaction — maybe $0.001, maybe $0.01 — happening thousands of times per minute across millions of agents. There’s no shopping cart here. No checkout flow. No “add to cart.” It’s closer to a stock exchange than a store. Agents are buying compute, data, and capabilities from each other
**Published:** 2026-02-16T20:31:59+00:00 # Money at Machine Speed David Waxman Feb 16, 2026 Last week, Coinbase launched the first crypto wallet infrastructure built specifically for AI agents.¹ Hours later, Stripe announced it was adopting the same underlying protocol.² Two of the most important payments companies in the world shipped agent payment products on the same day. We’ve spent the last few months researching this space at TenOneTen Ventures, and we think most people are underestimating how fast it’s moving. ## Agents Have a Money Problem We’ve gotten good at building AI agents that can reason, plan, and coordinate with each other. Impressively good. But there’s a comically basic thing most agents can’t do: pay for stuff. An agent finds the API it needs but can’t swipe a credit card. It negotiates with another agent but has no way to settle. It identifies cheaper cloud compute but can’t buy it. Every time money enters the picture, the agent stops and waits for a human. This is a little like building a fleet of self-driving trucks and then requiring a person to hand cash to every toll booth operator. The autonomy is real until the transaction isn’t. McKinsey projects $1 trillion in US retail agentic commerce by 2030, with global projections reaching $3–5 trillion.³ ChatGPT already handles over 50 million daily shopping queries.⁴ The demand is there. The plumbing to actually move money between machines is what’s been missing. Until, apparently, last week. ## What Agents Actually Need to Buy Before we get to who’s building what, it’s worth stopping on a point that most coverage of this space glosses over: the things agents need to pay for mostly don’t look like anything humans buy. Some of it is familiar. An agent booking a flight or ordering supplies — that’s just e-commerce with a different buyer. But the bigger and more interesting category is transactions that have no human equivalent at all. An agent needs a real-time pricing lookup from another agent’s database. That’s a fraction of a cent, settled instantly. It needs ten seconds of GPU time to run an inference. It needs to check a credit score, pull weather data for a logistics route, or access a proprietary dataset to answer a question. Each of these is a microtransaction — maybe $0.001, maybe $0.01 — happening thousands of times per minute across millions of agents. There’s no shopping cart here. No checkout flow. No “add to cart.” It’s closer to a stock exchange than a store. Agents are buying compute, data, and capabilities from each other in real time, programmatically, at a scale and speed that human-designed payment systems were never built to handle. This is also why — and I’ll admit my partners had to convince me of this — crypto ends up being necessary. My initial instinct was that traditional rails would be fine. But think about it: Visa’s minimum transaction fees would cost more than the thing being purchased. You can’t run a $0.001 payment through a syst
**Published:** 2026-03-19T21:14:50.941000+00:00 * March 19, 2026 [As OpenClaw enthusiasm grips China, schoolkids and retirees alike raise 'lobsters'](/technology/openclaw-enthusiasm-grips-china-schoolkids-retirees-alike-raise-lobsters-2026-03-19/) The AI agent, which can connect several hardware and software tools and learn from the data produced with much less human intervention than a chatbot, has gone viral in China. [](/technology/openclaw-enthusiasm-grips-china-schoolkids-retirees-alike-raise-lobsters-2026-03-19/) * March 20, 2026 [US charges three tied to Super Micro Computer with helping smuggle billions of dollars of AI chips to China](/world/us-charges-three-people-with-conspiring-divert-ai-tech-china-2026-03-19/) * March 19, 2026 [Nvidia to sell 1 million chips to Amazon by end of 2027 in cloud deal](/business/retail-consumer/nvidia-sell-1-million-chips-amazon-by-end-2027-cloud-deal-2026-03-19/) * March 19, 2026 [Hegseth wants Pentagon to dump Anthropic's Claude, but military users say it's not so easy](/business/hegseth-wants-pentagon-dump-anthropics-claude-military-users-say-its-not-so-easy-2026-03-19/) * ago [Tencent integrates WeChat with OpenClaw AI agent](/technology/tencent-integrates-wechat-with-openclaw-ai-agent-amid-china-tech-battle-2026-03-22/) --- ## Reuters Events Logo * Event [Momentum AI New York, opens new tab](https://events.reutersevents.com/momentum/nyc?utm_source=reutersAIpage) 27-28 Apr 2026 · New York, USA * Event [Momentum AI London, opens new tab](https://events.reutersevents.com/momentum/london?utm_source=reutersAIpage) 29-30 Jun 2026 · London, USA * Event [Momentum AI Austin, opens new tab](https://events.reutersevents.com/momentum?utm_source=reutersAIpage) 24-25 Sep 2026 · Austin, USA * Event [Momentum AI Finance, opens new tab](https://events.reutersevents.com/momentum/finance?utm_source=reutersAIpage) 16-17 Nov 2026 · New York, USA ## More Coverage
**Published:** 2026-03-19T21:14:50.941000+00:00 * March 19, 2026 [As OpenClaw enthusiasm grips China, schoolkids and retirees alike raise 'lobsters'](/technology/openclaw-enthusiasm-grips-china-schoolkids-retirees-alike-raise-lobsters-2026-03-19/) The AI agent, which can connect several hardware and software tools and learn from the data produced with much less human intervention than a chatbot, has gone viral in China. [](/technology/openclaw-enthusiasm-grips-china-schoolkids-retirees-alike-raise-lobsters-2026-03-19/) * March 20, 2026 [US charges three tied to Super Micro Computer with helping smuggle billions of dollars of AI chips to China](/world/us-charges-three-people-with-conspiring-divert-ai-tech-china-2026-03-19/) * March 19, 2026 [Nvidia to sell 1 million chips to Amazon by end of 2027 in cloud deal](/business/retail-consumer/nvidia-sell-1-million-chips-amazon-by-end-2027-cloud-deal-2026-03-19/) * March 19, 2026 [Hegseth wants Pentagon to dump Anthropic's Claude, but military users say it's not so easy](/business/hegseth-wants-pentagon-dump-anthropics-claude-military-users-say-its-not-so-easy-2026-03-19/) * ago [Tencent integrates WeChat with OpenClaw AI agent](/technology/tencent-integrates-wechat-with-openclaw-ai-agent-amid-china-tech-battle-2026-03-22/) --- ## Reuters Events Logo * Event [Momentum AI New York, opens new tab](https://events.reutersevents.com/momentum/nyc?utm_source=reutersAIpage) 27-28 Apr 2026 · New York, USA * Event [Momentum AI London, opens new tab](https://events.reutersevents.com/momentum/london?utm_source=reutersAIpage) 29-30 Jun 2026 · London, USA * Event [Momentum AI Austin, opens new tab](https://events.reutersevents.com/momentum?utm_source=reutersAIpage) 24-25 Sep 2026 · Austin, USA * Event [Momentum AI Finance, opens new tab](https://events.reutersevents.com/momentum/finance?utm_source=reutersAIpage) 16-17 Nov 2026 · New York, USA ## More Coverage
# Writes and Write-Nots | | | | | | --- | --- | --- | --- | | | | | | | --- | | Writes and Write-Nots October 2024 I'm usually reluctant to make predictions about technology, but I feel fairly confident about this one: in a couple decades there won't be many people who can write. One of the strangest things you learn if you're a writer is how many people have trouble writing. Doctors know how many people have a mole they're worried about; people who are good at setting up computers know how many people aren't; writers know how many people need help writing. The reason so many people have trouble writing is that it's fundamentally difficult. To write well you have to think clearly, and thinking clearly is hard. And yet writing pervades many jobs, and the more prestigious the job, the more writing it tends to require. These two powerful opposing forces, the pervasive expectation of writing and the irreducible difficulty of doing it, create enormous pressure. This is why eminent professors often turn out to have resorted to plagiarism. The most striking thing to me about these cases is the pettiness of the thefts. The stuff they steal is usually the most mundane boilerplate — the sort of thing that anyone who was even halfway decent at writing could turn out with no effort at all. Which means they're not even halfway decent at writing. Till recently there was no convenient escape valve for the pressure created by these opposing forces. You could pay someone to write for you, like JFK, or plagiarize, like MLK, but if you couldn't buy or steal words, you had to write them yourself. And as a result nearly everyone who was expected to write had to learn how. Not anymore. AI has blown this world open. Almost all pressure to write has dissipated. You can have AI do it for you, both in school and at work. The result will be a world divided into writes and write-nots. There will still be some people who can write. Some of us like it. But the middle ground between those who are good at writing and those who can't write at all will disappear. Instead of good writers, ok writers, and people who can't write, there will just be good writers and people who can't write. Is that so bad? Isn't it common for skills to disappear when technology makes them obsolete? There aren't many blacksmiths left, and it doesn't seem to be a problem. Yes, it's bad. The reason is something I mentioned earlier: writing is thinking. In fact there's a kind of thinking that can only be done by writing. You can't make this point better than Leslie Lamport did: If you're thinking without writing, you only think you're thinking. So a world divided into writes and write-nots is more dangerous than it sounds. It will be a world of thinks and think-nots. I know which half I want to be in, and I bet you do too. This situation is not unprecedented. In preindustrial times most people's jobs made them strong. Now if you want to be strong, you work out. So there are still stron
# Writes and Write-Nots October 2024 I'm usually reluctant to make predictions about technology, but I feel fairly confident about this one: in a couple decades there won't be many people who can write. One of the strangest things you learn if you're a writer is how many people have trouble writing. Doctors know how many people have a mole they're worried about; people who are good at setting up computers know how many people aren't; writers know how many people need help writing. The reason so many people have trouble writing is that it's fundamentally difficult. To write well you have to think clearly, and thinking clearly is hard. And yet writing pervades many jobs, and the more prestigious the job, the more writing it tends to require. These two powerful opposing forces, the pervasive expectation of writing and the irreducible difficulty of doing it, create enormous pressure. This is why eminent professors often turn out to have resorted to plagiarism. The most striking thing to me about these cases is the pettiness of the thefts. The stuff they steal is usually the most mundane boilerplate — the sort of thing that anyone who was even halfway decent at writing could turn out with no effort at all. Which means they're not even halfway decent at writing. Till recently there was no convenient escape valve for the pressure created by these opposing forces. You could pay someone to write for you, like JFK, or plagiarize, like MLK, but if you couldn't buy or steal words, you had to write them yourself. And as a result nearly everyone who was expected to write had to learn how. Not anymore. AI has blown this world open. Almost all pressure to write has dissipated. You can have AI do it for you, both in school and at work. The result will be a world divided into writes and write-nots. There will still be some people who can write. Some of us like it. But the middle ground between those who are good at writing and those who can't write at all will disappear. Instead of good writers, ok writers, and people who can't write, there will just be good writers and people who can't write. Is that so bad? Isn't it common for skills to disappear when technology makes them obsolete? There aren't many blacksmiths left, and it doesn't seem to be a problem. Yes, it's bad. The reason is something I mentioned earlier: writing is thinking. In fact there's a kind of thinking that can only be done by writing. You can't make this point better than Leslie Lamport did: If you're thinking without writing, you only think you're thinking. So a world divided into writes and write-nots is more dangerous than it sounds. It will be a world of thinks and think-nots. I know which half I want to be in, and I bet you do too. This situation is not unprecedented. In preindustrial times most people's jobs made them strong. Now if you want to be strong, you work out. So there are still strong people, but only those who choose to be. It will be the same with writing. There wi
**Published:** 2021-03-13T18:18:43.264000+00:00 # Software 2.0 [](/?source=post_page---byline--a64152b37c35---------------------------------------) [Andrej Karpathy](/?source=post_page---byline--a64152b37c35---------------------------------------) 9 min read · Nov 11, 2017 -- 189 Listen Share I sometimes see people refer to neural networks as just “another tool in your machine learning toolbox”. They have some pros and cons, they work here or there, and sometimes you can use them to win Kaggle competitions. Unfortunately, this interpretation completely misses the forest for the trees. Neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we develop software. They are Software 2.0. The “classical stack” of **Software 1.0** is what we’re all familiar with — it is written in languages such as Python, C++, etc. It consists of explicit instructions to the computer written by a programmer. By writing each line of code, the programmer identifies a specific point in program space with some desirable behavior. Press enter or click to view image in full size ![]() In contrast, **Software 2.0** is written in much more abstract, human unfriendly language, such as the weights of a neural network. No human is involved in writing this code because there are a lot of weights (typical networks might have millions), and coding directly in weights is kind of hard (I tried). Press enter or click to view image in full size ![]() Instead, our approach is to specify some goal on the behavior of a desirable program (e.g., “satisfy a dataset of input output pairs of examples”, or “win a game of Go”), write a rough skeleton of the code (i.e. a neural net architecture) that identifies a subset of program space to search, and use the computational resources at our disposal to search this space for a program that works. In the case of neural networks, we restrict the search to a continuous subset of the program space where the search process can be made (somewhat surprisingly) efficient with backpropagation and stochastic gradient descent. Press enter or click to view image in full size ![]() To make the analogy explicit, in Software 1.0, human-engineered source code (e.g. some .cpp files) is compiled into a binary that does useful work. In Software 2.0 most often the source code comprises 1) the dataset that defines the desirable behavior and 2) the neural net architecture that gives the rough skeleton of the code, but with many details (the weights) to be filled in. The process of training the neural network compiles the dataset into the binary — the final neural network. In most practical applications today, the neural net architectures and the training systems are increasingly standardized into a commodity, so most of the active “software development” takes the form of curating, growing, massaging and cleaning
**Published:** 2021-03-13T18:18:43.264000+00:00 # Software 2.0 Andrej Karpathy Nov 11, 2017 I sometimes see people refer to neural networks as just “another tool in your machine learning toolbox”. They have some pros and cons, they work here or there, and sometimes you can use them to win Kaggle competitions. Unfortunately, this interpretation completely misses the forest for the trees. Neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we develop software. They are Software 2.0. The “classical stack” of **Software 1.0** is what we’re all familiar with — it is written in languages such as Python, C++, etc. It consists of explicit instructions to the computer written by a programmer. By writing each line of code, the programmer identifies a specific point in program space with some desirable behavior. In contrast, **Software 2.0** is written in much more abstract, human unfriendly language, such as the weights of a neural network. No human is involved in writing this code because there are a lot of weights (typical networks might have millions), and coding directly in weights is kind of hard (I tried). Instead, our approach is to specify some goal on the behavior of a desirable program (e.g., “satisfy a dataset of input output pairs of examples”, or “win a game of Go”), write a rough skeleton of the code (i.e. a neural net architecture) that identifies a subset of program space to search, and use the computational resources at our disposal to search this space for a program that works. In the case of neural networks, we restrict the search to a continuous subset of the program space where the search process can be made (somewhat surprisingly) efficient with backpropagation and stochastic gradient descent. To make the analogy explicit, in Software 1.0, human-engineered source code (e.g. some .cpp files) is compiled into a binary that does useful work. In Software 2.0 most often the source code comprises 1) the dataset that defines the desirable behavior and 2) the neural net architecture that gives the rough skeleton of the code, but with many details (the weights) to be filled in. The process of training the neural network compiles the dataset into the binary — the final neural network. In most practical applications today, the neural net architectures and the training systems are increasingly standardized into a commodity, so most of the active “software development” takes the form of curating, growing, massaging and cleaning labeled datasets. This is fundamentally altering the programming paradigm by which we iterate on our software, as the teams split in two: the 2.0 programmers (data labelers) edit and grow the datasets, while a few 1.0 programmers maintain and iterate on the surrounding training code infrastructure, analytics, visualizations and labeling interfaces. It turns out that a large portion of real-world problems have the property that it is significantly easier to col
asyncio — Asynchronous I/O — Python 3.14.3 documentation # `asyncio` — Asynchronous I/O[¶](#module-asyncio "Link to this heading") --- asyncio is a library to write **concurrent** code using the **async/await** syntax. asyncio is used as a foundation for multiple Python asynchronous frameworks that provide high-performance network and web-servers, database connection libraries, distributed task queues, etc. asyncio is often a perfect fit for IO-bound and high-level **structured** network code. See also [A Conceptual Overview of asyncio](../howto/a-conceptual-overview-of-asyncio.html#a-conceptual-overview-of-asyncio) : Explanation of the fundamentals of asyncio. asyncio provides a set of **high-level** APIs to: * [run Python coroutines](asyncio-task.html#coroutine) concurrently and have full control over their execution; * perform [network IO and IPC](asyncio-stream.html#asyncio-streams); * control [subprocesses](asyncio-subprocess.html#asyncio-subprocess); * distribute tasks via [queues](asyncio-queue.html#asyncio-queues); * [synchronize](asyncio-sync.html#asyncio-sync) concurrent code; Additionally, there are **low-level** APIs for *library and framework developers* to: * create and manage [event loops](asyncio-eventloop.html#asyncio-event-loop), which provide asynchronous APIs for [networking](asyncio-eventloop.html#loop-create-server), running [subprocesses](asyncio-eventloop.html#loop-subprocess-exec), handling [OS signals](asyncio-eventloop.html#loop-add-signal-handler), etc; * implement efficient protocols using [transports](asyncio-protocol.html#asyncio-transports-protocols); * [bridge](asyncio-future.html#asyncio-futures) callback-based libraries and code with async/await syntax. [Availability](intro.html#availability): not WASI. This module does not work or is not available on WebAssembly. See [WebAssembly platforms](intro.html#wasm-availability) for more information. asyncio REPL You can experiment with an `asyncio` concurrent context in the [REPL](../glossary.html#term-REPL): ``` $ python -m asyncio asyncio REPL ... Use "await" directly instead of "asyncio.run()". Type "help", "copyright", "credits" or "license" for more information. >>> import asyncio >>> await asyncio.sleep(10, result='hello') 'hello' ``` This REPL provides limited compatibility with [`PYTHON_BASIC_REPL`](../using/cmdline.html#envvar-PYTHON_BASIC_REPL). It is recommended that the default REPL is used for full functionality and the latest features. Raises an [auditing event](sys.html#auditing) `cpython.run_stdin` with no arguments. Changed in version 3.12.5: (also 3.11.10, 3.10.15, 3.9.20, and 3.8.20) Emits audit events. Changed in version 3.13: Uses PyREPL if possible, in which case [`PYTHONSTARTUP`](../using/cmdline.html#envvar-PYTHONSTARTUP) is also executed. Emits audit events. Reference High-level APIs * [Runners](asyncio-runner.html) * [Coroutines and tasks](asyncio-task.html) * [Streams](asyncio-stream.html) * [Synchronizati
asyncio — Asynchronous I/O — Python 3.14.3 documentation # `asyncio` — Asynchronous I/O asyncio is a library to write **concurrent** code using the **async/await** syntax. asyncio is used as a foundation for multiple Python asynchronous frameworks that provide high-performance network and web-servers, database connection libraries, distributed task queues, etc. asyncio is often a perfect fit for IO-bound and high-level **structured** network code. See also A Conceptual Overview of asyncio : Explanation of the fundamentals of asyncio. asyncio provides a set of **high-level** APIs to: * run Python coroutines concurrently and have full control over their execution; * perform network IO and IPC; * control subprocesses; * distribute tasks via queues; * synchronize concurrent code; Additionally, there are **low-level** APIs for *library and framework developers* to: * create and manage event loops, which provide asynchronous APIs for networking, running subprocesses, handling OS signals, etc; * implement efficient protocols using transports; * bridge callback-based libraries and code with async/await syntax. Availability: not WASI. This module does not work or is not available on WebAssembly. See WebAssembly platforms for more information. asyncio REPL You can experiment with an `asyncio` concurrent context in the REPL: ``` $ python -m asyncio asyncio REPL ... Use "await" directly instead of "asyncio.run()". Type "help", "copyright", "credits" or "license" for more information. >>> import asyncio >>> await asyncio.sleep(10, result='hello') 'hello' ``` This REPL provides limited compatibility with `PYTHON_BASIC_REPL`. It is recommended that the default REPL is used for full functionality and the latest features. Raises an auditing event `cpython.run_stdin` with no arguments. Changed in version 3.12.5: (also 3.11.10, 3.10.15, 3.9.20, and 3.8.20) Emits audit events. Changed in version 3.13: Uses PyREPL if possible, in which case `PYTHONSTARTUP` is also executed. Emits audit events. Reference High-level APIs * Runners * Coroutines and tasks * Streams * Synchronization Primitives * Subprocesses * Queues * Exceptions * Call Graph Introspection Low-level APIs * Event loop * Futures * Transports and Protocols * Policies * Platform Support * Extending Guides and Tutorials * High-level API Index * Low-level API Index * Developing with asyncio Note The source code for asyncio can be found in Lib/asyncio/.
# [no-title] Sorry.
# [no-title] Sorry.
Announcements # Introducing Claude 4 May 22, 2025  Today, we’re introducing the next generation of Claude models: **Claude Opus 4** and **Claude Sonnet 4**, setting new standards for coding, advanced reasoning, and AI agents. Claude Opus 4 is the world’s best coding model, with sustained performance on complex, long-running tasks and agent workflows. Claude Sonnet 4 is a significant upgrade to Claude Sonnet 3.7, delivering superior coding and reasoning while responding more precisely to your instructions. Alongside the models, we're also announcing: * **Extended thinking with tool use (beta)**: Both models can use tools—like [web search](https://docs.anthropic.com/en/docs/build-with-claude/tool-use/web-search-tool)—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. * **New model capabilities**: Both models can use tools in parallel, follow instructions more precisely, and—when given access to local files by developers—demonstrate significantly improved memory capabilities, extracting and saving key facts to maintain continuity and build tacit knowledge over time. * **Claude Code is now generally available**: After receiving extensive positive feedback during our research preview, we’re expanding how developers can collaborate with Claude. Claude Code now supports background tasks via GitHub Actions and native integrations with VS Code and JetBrains, displaying edits directly in your files for seamless pair programming. * **New API capabilities:** We’re releasing [four new capabilities](https://www.anthropic.com/news/agent-capabilities-api) on our API that enable developers to build more powerful AI agents: the code execution tool, MCP connector, Files API, and the ability to cache prompts for up to one hour. Claude Opus 4 and Sonnet 4 are hybrid models offering two modes: near-instant responses and extended thinking for deeper reasoning. The Pro, Max, Team, and Enterprise Claude plans include both models and extended thinking, with Sonnet 4 also available to free users. Both models are available on our API, Amazon Bedrock, and Google Cloud's Vertex AI. Pricing remains consistent with previous Opus and Sonnet models: Opus 4 at $15/$75 per million tokens (input/output) and Sonnet 4 at $3/$15. ## Claude 4 Claude Opus 4 is our most powerful model yet and the best coding model in the world, leading on SWE-bench (72.5%) and Terminal-bench (43.2%). It delivers sustained performance on long-running tasks that require focused effort and thousands of steps, with the ability to work continuously for several hours—dramatically outperforming all Sonnet models and significantly expanding what AI agents can accomplish. Claude Opus 4 excels at coding and complex problem-solving, powering frontier agent products. **Cursor** calls it state-of-the-art for coding and a
# Introducing Claude 4 May 22, 2025  Today, we’re introducing the next generation of Claude models: **Claude Opus 4** and **Claude Sonnet 4**, setting new standards for coding, advanced reasoning, and AI agents. Claude Opus 4 is the world’s best coding model, with sustained performance on complex, long-running tasks and agent workflows. Claude Sonnet 4 is a significant upgrade to Claude Sonnet 3.7, delivering superior coding and reasoning while responding more precisely to your instructions. Alongside the models, we're also announcing: * **Extended thinking with tool use (beta)**: Both models can use tools—like [web search](https://docs.anthropic.com/en/docs/build-with-claude/tool-use/web-search-tool)—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. * **New model capabilities**: Both models can use tools in parallel, follow instructions more precisely, and—when given access to local files by developers—demonstrate significantly improved memory capabilities, extracting and saving key facts to maintain continuity and build tacit knowledge over time. * **Claude Code is now generally available**: After receiving extensive positive feedback during our research preview, we’re expanding how developers can collaborate with Claude. Claude Code now supports background tasks via GitHub Actions and native integrations with VS Code and JetBrains, displaying edits directly in your files for seamless pair programming. * **New API capabilities:** We’re releasing [four new capabilities](https://www.anthropic.com/news/agent-capabilities-api) on our API that enable developers to build more powerful AI agents: the code execution tool, MCP connector, Files API, and the ability to cache prompts for up to one hour. Claude Opus 4 and Sonnet 4 are hybrid models offering two modes: near-instant responses and extended thinking for deeper reasoning. The Pro, Max, Team, and Enterprise Claude plans include both models and extended thinking, with Sonnet 4 also available to free users. Both models are available on our API, Amazon Bedrock, and Google Cloud's Vertex AI. Pricing remains consistent with previous Opus and Sonnet models: Opus 4 at $15/$75 per million tokens (input/output) and Sonnet 4 at $3/$15. ## Claude 4 Claude Opus 4 is our most powerful model yet and the best coding model in the world, leading on SWE-bench (72.5%) and Terminal-bench (43.2%). It delivers sustained performance on long-running tasks that require focused effort and thousands of steps, with the ability to work continuously for several hours—dramatically outperforming all Sonnet models and significantly expanding what AI agents can accomplish. Claude Opus 4 excels at coding and complex problem-solving, powering frontier agent products. **Cursor** calls it state-of-the-art for coding and a leap forward i